
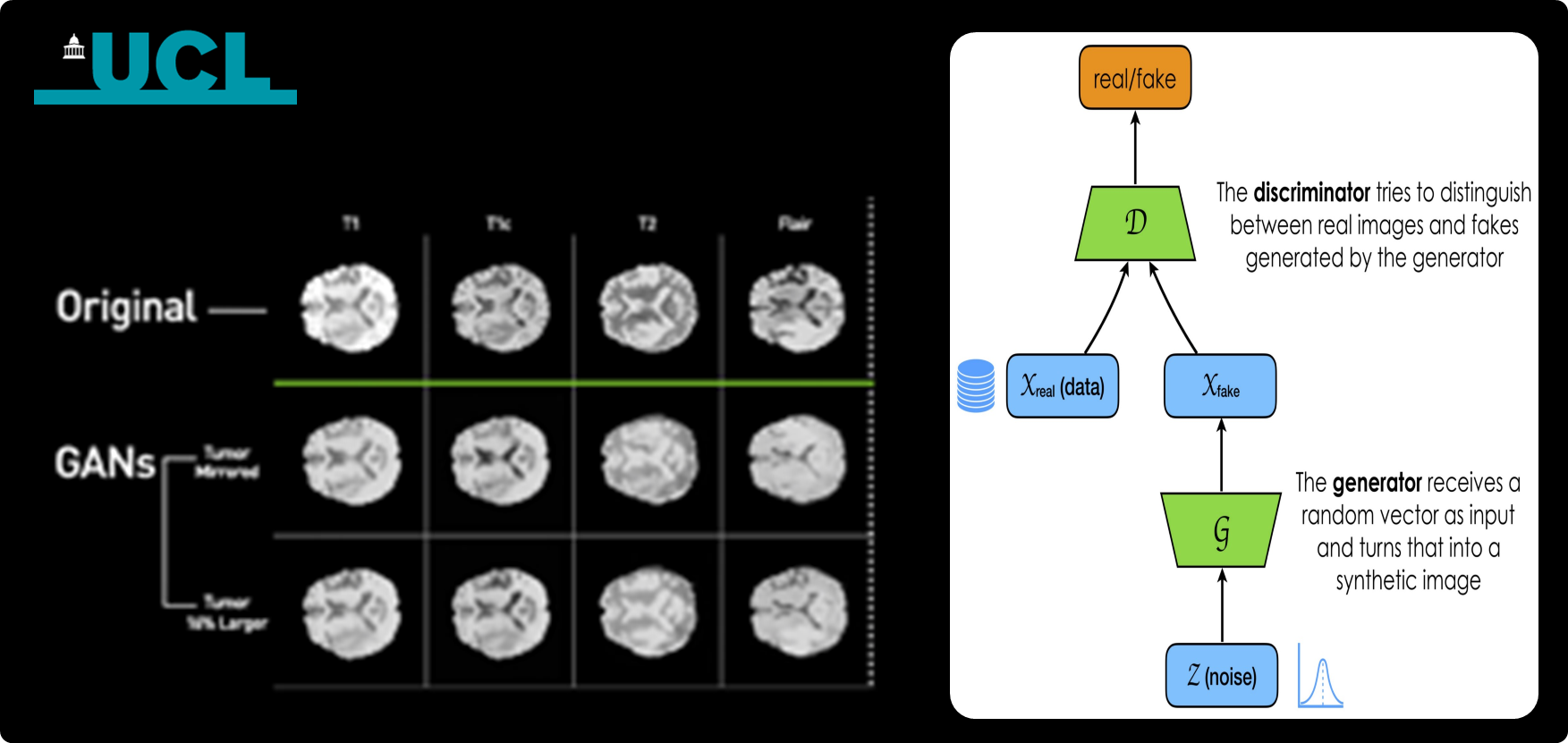
In rare diseases, data is scarce and precious. Research teams need more samples to train reliable models without compromising privacy or fidelity. We partnered to build a safe pipeline that expands limited cohorts into rigorous training datasets for detection and progression modeling.
Context
Small, heterogeneous cohorts (medical images, labs) increase variance and overfitting risk. Labels are expensive; sharing is constrained. The goal: generate and curate additional training data so models generalize better while preserving patient privacy.
Approach
- Curation. Cohort harmonization, quality checks, and leakage prevention; de-identification and governance.
- Augmentation. Domain-aware transforms (intensity, geometry), mixup/cutout, and class-balancing strategies.
- Synthetic data. Generative models (GANs/diffusion/VAEs) tuned with clinician input; realism and diversity validated by blinded experts.
- Training + eval. Stratified cross-validation; calibration, sensitivity/specificity tracking; bias and drift checks.
- Safety. Privacy risk assessments (nearest-neighbor, membership inference), reproducible lineage, and review trails.
Impact
- Data volume: created substantially larger, balanced training sets from limited cohorts.
- Accuracy: improved sensitivity/ROC on held-out data with clinician-audited fidelity.
- Velocity: faster experimentation cycles with reusable curation + generation templates.
Dataset Size
1 -> 4
300%+ increase
Accuracy
-> 80%+
Sensitivity on hold-out
Cycle Time
Weeks -> Days
Experimentation velocity
Note: engagement ongoing; metrics indicative of early pilots. All work follows strict privacy and ethics oversight.